TRIPLE 与 DOUBLE 的问题
远在硬件加速的图形系统 ( graphics APIs ) 出现前,double-buffer 已经是流行的动画防闪烁技术,这个名称一直沿用到 OpenGL 之类硬件加速系统上的相似技术。而 Metal 之类低开销图形系统 ( low-overhead graphics APIs ) 的标准运行模式是 triple-buffer。同时看到这两个名称会引出几个问题:
- 为什么低开销系统采用「triple」,而不是「double」或者「quad」?
- 在代码里「triple」是如何体现的?
- 和「double-buffer」相比,「triple」是仅仅多了一个 frame buffer 吗?
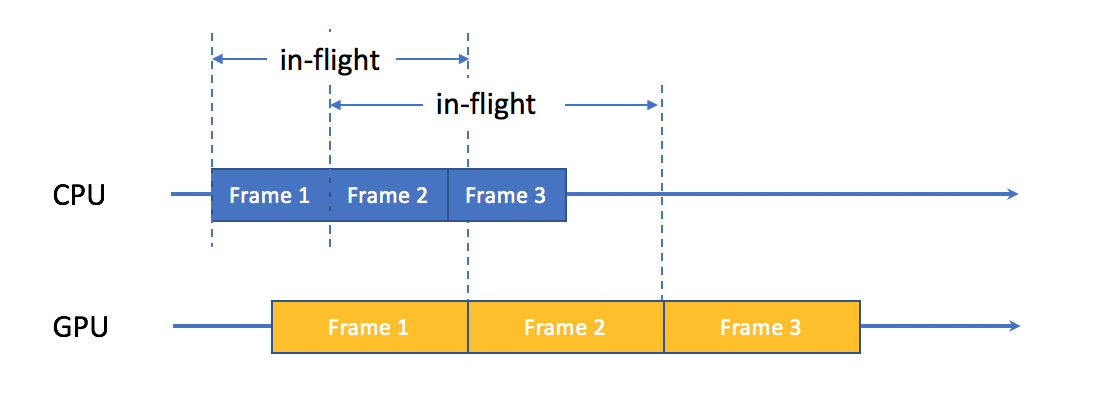
深入讨论前先统一几个术语,因为各个图形系统常用不同名称指代相近的概念。CPU-GPU 工作在 client-server 模式。图形系统的驱动 ( driver ) 负责发送 CPU 的 request 给 GPU。发送前 CPU 准备 request 数据的过程叫「encoding」。GPU 执行 request 的过程叫「rendering」。每个 request 携带少量的参数,如各种变换矩阵,叫 parameter buffer。存储 rendering 结果的区域叫 frame buffer。[1] [2] [3] 一个 frame encoding 开始到 rendering 结束这段时间称为「in-flight」状态。图 1 显示了 OpenGL 系统各个过程执行的时间顺序。

图 1 Single In-Flight Frame
为了简化同步机制,OpenGL 系统里一个 frame 的 encoding 要等前一个 frame 的 rendering 结束后才开始。任意时刻最多存在一个 in-flight。这样 CPU 和 GPU 都无法避免空闲等待的状态。如上图所示调用 glFlush() 或者 glutSwapBuffers() 导致 CPU 的 idle 时段。从 encoding 到 rendering 的延时会导致 GPU 的 idle 时段。以这张图为基础,我们讨论下面这个问题:
- 如果利用 multi-buffer 机制,至少需要几个 buffer 才能缩短空闲时间?Double-buffer 可以吗?特别的,OpenGL 风格的 double-buffer 可以吗?更多的 buffer 有帮助吗,还是反而起负面作用? ( n-buffer 中的 n 取什么值合适?)
BUFFER 与空闲时间
设想一个「naïve solution」:如果有许多个 frame buffer,GPU rendering 时把不同的 frame 写到不同的 frame buffer 里,似乎可以按照图 2 的方式同时执行多个 in-flight 过程。

图 2 Naïve Multiple In-flight Frames
那么来看看这个方案「naïve」在何处。如果在 GPU-bound 应用 [4] 中放任 CPU 无限制地 encoding 下去,CPU 和 GPU 间的处理延时会越来越大。这种延时导致需要暂存的 rendering 结果没有上限。所以一个可行的方案必须有办法让 CPU 适度地停下来等 GPU,这样延时可以控制在常数范围,有限的 buffer 也可以被循环利用。低开销图形系统希望最终达到图 3 的状态,这时系统的处理延时为 d frames,最多有 d+1 个 in-flight。GPU 达到满负荷,同时与 CPU 的延时始终保持在合理范围。

图 3 低开销图形系统的稳定状态
要做到这点,低开销图形系统需要跟踪有多少 frames 处于 in-flight 状态。Metal 利用 command buffer 实现这个机制,其它低开销系统也有类似概念。OpenGL 系统没有类似概念,只能通过调用 glFlush() 或 glutSwapBuffers() 让 CPU 等待 GPU 运行完所有的 requests (图 1)。即使有 multi-buffer,仅支持单个 in-flight 的图形系统只能消除闪烁,并不能减少等待时间。
第二个问题是,parameter buffer 在 encoding 过程中被 CPU 写入,在 rendering 过程中被 GPU 读出。当多个 frame 处于 in-flight 状态时,必须为它们分别分配 parameter buffer,不能重用。否则后来的 encoding 会破坏前面 rendering 过程读出数据。OpenGL 采用的 uniform 方式限制了由同一 shader 处理的所有 frames 共享同一个 parameter buffer。回到之前的问题:「OpenGL 风格的 double-buffer 可以吗?」—— 一般意义上的 double-buffer「有可能」降低空闲等待时间,但是 OpenGL 风格的并不能,因为缺乏跟踪 in-flight 机制和相应的 parameter buffer 分配机制。
SHOW ME THE CODE
现在具体看一下「跟踪 in-flight 状态」的机制在基于 Metal 的代码里的具体实现。下面的两段 code 从 Nuo Model Viewer 的 in-flight 处理简化而来。
// setup n-buffer, n is 3 in most cases
const unsigned int kInFlightBufferCount = n;
...
// in app initialization, _displaySemaphore was
// initialized with re-entry maximal number
// "kInFlightCount"
_displaySemaphore =
dispatch_semaphore_create(kInFlightBufferCount);
代码段 1 初始化
代码段 1 是应用在初始化时设置变量。常量 kInFlightBufferCount 作为 _displaySemaphore 的初始化参数决定了 in-flight 的最大数,也就是 n-buffer 运行模式的 n。
dispatch_semaphore_wait(_displaySemaphore,
DISPATCH_TIME_FOREVER);
id<MTLCommandBuffer> commandBuffer = ...
_inFlightIndex = (_inFlightIndex + 1) % kInFlightCount;
// encoding on the command buffer on the
// "_inFlightIndex"th buffer
...
[commandBuffer commit];
[commandBuffer addCompletedHandler:^
(id<MTLCommandBuffer> commandBuffer)
{
...
dispatch_semaphore_signal(_displaySemaphore);
}];
代码段 2 In-flight 处理
代码段 2 是每个 frame 处理 in-flight 的逻辑。其中 semaphore_wait 和 semaphore_signal 定义的 critical region 正好符合图 3 所示的 in-flight 过程。和传统教科书基于 PV 操作的 critical region 相比,这个 region 有两个特殊性。第一,它不是严格的互斥访问,而是由 _displaySemaphore 指定重入的最大次数。第二,它的起始点和结束点不在同一段 sequential code 中,而是分别在 main thread 与 command buffer complete-handler 中。所以它不是控制不同 thread 的并发访问,而是用 GPU 通知来控制 main thread 的等待,以达到图 3 的效果。绝大多数情况下,Metal 系统的 _displaySemaphore 初始化参数为 3,即 triple-buffer。
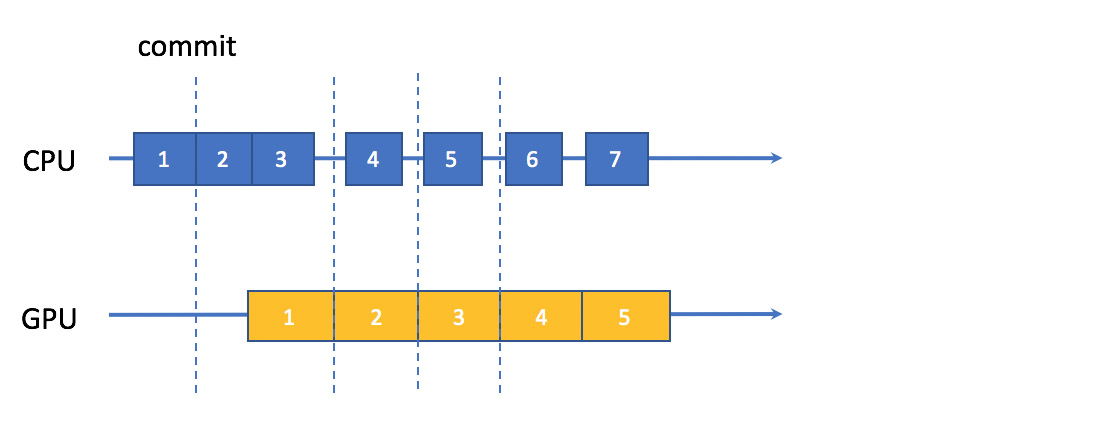
其中第 5 行计算当前选择的 buffer 序号。因为运行在 n-buffer 模式,所以用 % 在 kInFlightBufferCount 个 buffer 里依次循环重用。第 11 行调用 commit,表示一个 frame 的所有 encoding 完全结束后才会发出 request 让 GPU 开始 rendering。图 2 和图 3 里那种 GPU 在一个 frame 的 CPU encoding 进行中就开始 rendering 的情况并不会在 Metal 系统中出现 [5]。如图 4 显示了允许三个 in-flight 时 Metal 系统的时序。可以看到由于 commit,延时比图 2 要长。

图 4 Metal 的初始时序
从这段代码也可以看出,Metal 的 n-buffer 中 n 可以任意取值。这是低开销图形系统的一般特点 —— 并不在 APIs 定义中硬性规定 n 的具体值。下面讨论 什么取值能最大地释放系统性能。
TRIPLE 和最优性能
上面的讨论中可以看到,_displaySemaphore 定义的重入次数决定了整个系统运行在 n-buffer 模式。现在讨论 n 的取值对性能的影响。当 n 设置为 5 时 ( quintuple-buffer ) 系统运行如图 5 所示。

图 5 Quintuple-Buffer 的时序
系统在第 10 个 frame 达到稳定状态,延时为四个 frame。除了延时增加之外,还必须准备五套 parameter buffer 和 frame buffer。因此 in-flight 过多有弊无利。如果采取相反的措施,降低 in-flight 个数是否可以减少延时?这时要注意到,在图 4 和图 5 中第一个 frame 的 encoding 和 rendering 之间的延时是 CPU-GPU 作为 client-server 系统的固有延时。从 Apple 文档中摘抄的图 6 大致描述了固有延时的构成。这里「Complete Frame …」可以粗略的看作上文的 rendering 过程。

图 6 CPU-GPU 固有延时
虽然 CPU-GPU 的固有延时并不能通过本篇讨论精确得出,但从图 6 和图 5 来考虑,不妨大致假设为每个 frame encoding 时长的 3/4。如果把 in-flight 最大数设置为 2,系统的时序如图 7 所示。

图 7 Metal 风格的 double-buffer 时序
由此可以看出,相对于 OpenGL 系统,Metal 风格的 double-buffer 可以减少一部分空闲等待时间,但是 CPU-GPU 的固有延时决定了 double-buffer 并不能完全消除所有的空闲等待。只有 kInFlightBufferCount 为 3 的 triple-buffer 模式才能达到图 3 和图 4 中 GPU 没有空闲等待的情况。
结论
最后总结一下篇头提出的所有问题。
为什么低开销系统采用「triple」,而不是「double」或者「quad」?
本篇并不能精确证明 triple 在任何情况下都是最优解。但可以分析出,过高的 in-flight 最大数会增加 rendering 延时,过低会导致 GPU 空闲等待。Triple 是针对一般情况的最佳设定。
在代码里「triple」是如何体现的?
通过规定可以重入三次的 semaphore。
和「double-buffer」相比,「triple」是仅仅多了一个 frame buffer 吗?
OpenGL 风格的 double-buffer 只涉及 frame buffer。 低开销图形系统的 triple-buffer 则涉及 frame buffer,parameter buffer 以及基于 semaphore 的 CPU-GPU 同步方式。更确切的说,triple-buffer 应该被称作 triple-in-flight。
如果利用 multi-buffer 机制,至少需要几个 buffer 才能缩短空闲时间? Double-buffer 可以吗?特别的,OpenGL 风格的 double-buffer 可以吗?更多的 buffer 有帮助吗,还是反而起负面作用? ( n-buffer 中的 n 取什么值合适?)
采用基于 semaphore 的同步方式,多于一个 in-flight 的系统就可以缩短空闲时间。对于 GPU-bound 应用,通常三个 in-flight 能完全消除等待时间。OpenGL 没有跟踪 in-flight 的能力,其 double-buffer 只能消除闪烁。过多和过少的 in-flight 数目都对性能起负面作用。
脚注:
- 术语「encoding」来自于 Metal 系统。OpenGL 里并没有对应的名字。
- 术语「parameter buffer」在 OpenGL 里对应 uniform,在 Metal 里是作为 shader function parameter 的 buffer。
- 术语「frame buffer」来自于 OpenGL。在 Metal 里对应于用作 rendering target 的 texture。
- GPU rendering 的时间大于 CPU encoding 时间。本文只讨论这种情况,对于 CPU-bound 应用请作为读后思考。
- OpenGL 系统的 encoding 可以看作每个 request 立即被 commit,而不是一个 frame 的所有 requests 被一次 commit。