最近儿子快要上高中。Twitter 上有些人在讨论教育。这些因素让我也回忆起以前自己上学的事情。我中学阶段也算优秀。初中自学完高中物理。高中尝试了两次学习高等数学。但是这两次都功亏一溃。怎么说功亏一溃呢?其实积分都学的差不多了,就差最后练习一些移项凑项的技巧,然后学会极坐标和多重积分就行了。而这些东西对于高一的我有巨大意义。因为我刚得过北京市物理奥林匹克竞赛二等奖,下一步就可以去参加需要微积分知识的高一级竞赛。
但就在这个时候我卡在了一个概念上。因为这个概念过不去,年少轻狂我就不去物理奥校了!当然那时候高考还是绝对的指挥棒,靠竞赛路径找好学校还不流行。不过回想起来也是草率的可以。
什么概念这么神奇呢?看下面这个式子:

大多数有高数知识的人都能轻易解出来:

但这里隐藏了一个问题,就是第一步把 x 和 dx 结合了起来。而在大学微积分教材里明确写过:被积函数是一个整体,积分变量只是作为标记放在一旁。而另一方面,对于加法,会采用分配率:
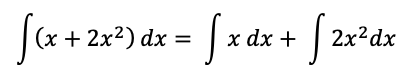
所以一方面我们说 dx 不是一个因子,另一方面我们又在按照乘法的分配率和结合律来操作它。当我提出这个问题的时候,老师告诉我:你能算出答案就行了。我当时的信念就有些崩塌了。我也不是太形而上的人,但是高中就挺累的,如果没有点儿 bigger than life 的意义,我就丧失了额外求学的动力。
直到去年夏天因为各种因素不得不学习 machine learning 的时候,再次看到 chain rule of derivative,才豁然开朗。求第一个式子实际上是寻找 f(x) 满足:

但根据 chain-rule,我们也可以把想得到的答案形式改一下,变成寻找 f(g(x)),满足:
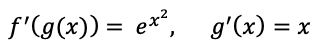
这个时候,我们对 g(x) 先求积分的形式,就等同于上面把 x 和 dx 先结合。虽然类似乘法操作,但是意义又不是乘法。回想起来当年就此放弃了高中时代对大学物理的早修,有点儿唏嘘。当年物理奥校是在人大附中,我每个周日从东直门骑车到了那里又不想去学,就到中关村闲逛,几年以后走上了程序员的道路。














